func CalcDot(a, b []float32) float32 {
var dot float32 = 0.0
size := len(a)
for i := 0; i < size; i++ {
dot += a[i] * b[i]
}
return dot
}続・Goによるdot積のベンチマーク
Go
線形代数
はじめに
WeaviateというGo実装の類似ベクトル検索エンジンで使用しているdot積が非常に早そうだったので再度ベンチマークを取ってみました。
やったこと
- Weaviateのdot積をベンチマーク対象に追加
- ベンチマーク条件変更
- データ型をfloat32に変更
- GOMAXPROCSを1に設定
Weaviateのdot積について
Weaviateのdot積、avoに生成されたアセンブリコードとして提供されています。 動作環境はAVX2がサポートされている必要がありますが、環境では非常に高速な動作が期待できます。
対象コード
単純なループによる実装
ループアンロールによる実装(N=2)
func CalcDotUnroll2(a, b []float32) float32 {
const N = 2
var dot float32 = 0.0
i := 0
size := len(a)
prologue_size := size % N
for ; i < prologue_size; i++ {
dot += a[i] * b[i]
}
for ; i < size; i += N {
mul0 := a[i+0] * b[i+0]
mul1 := a[i+1] * b[i+1]
dot += mul0 + mul1
}
return dot
}ループアンロールによる実装(N=4)
func CalcDotUnroll4(a, b []float32) float32 {
const N = 4
var dot float32 = 0.0
i := 0
size := len(a)
prologue_size := size % N
for ; i < prologue_size; i++ {
dot += a[i] * b[i]
}
for ; i < size; i += N {
mul0 := a[i+0] * b[i+0]
mul1 := a[i+1] * b[i+1]
mul2 := a[i+2] * b[i+2]
mul3 := a[i+3] * b[i+3]
dot += mul0 + mul1 + mul2 + mul3
}
return dot
}ループアンロールによる実装(N=8)
func CalcDotUnroll8(a, b []float32) float32 {
const N = 8
var dot float32 = 0.0
i := 0
size := len(a)
prologue_size := size % N
for ; i < prologue_size; i++ {
dot += a[i] * b[i]
}
for ; i < size; i += N {
mul0 := a[i+0] * b[i+0]
mul1 := a[i+1] * b[i+1]
mul2 := a[i+2] * b[i+2]
mul3 := a[i+3] * b[i+3]
mul4 := a[i+4] * b[i+4]
mul5 := a[i+5] * b[i+5]
mul6 := a[i+6] * b[i+6]
mul7 := a[i+7] * b[i+7]
dot += mul0 + mul1 + mul2 + mul3 + mul4 + mul5 + mul6 + mul7
}
return dot
}Gonumによる実装(blas)
import (
"gonum.org/v1/gonum/blas/blas32"
)
func CalcDotByGonumBlas(a, b []float32) float32 {
size := len(a)
av := blas32.Vector{
N: size,
Inc: 1,
Data: a,
}
bv := blas32.Vector{
N: size,
Inc: 1,
Data: b,
}
return blas32.Dot(av, bv)
}Weaviateによる実装(asm)
import (
"github.com/semi-technologies/weaviate/adapters/repos/db/vector/hnsw/distancer/asm"
)
func CalcDotByWeaviateAsm(a, b []float32) float32 {
return asm.Dot(a, b)
}ベンチマーク
実行環境
$lscpuArchitecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 43 bits physical, 48 bits virtual
CPU(s): 32
On-line CPU(s) list: 0-31
Thread(s) per core: 2
Core(s) per socket: 16
Socket(s): 1
NUMA node(s): 1
Vendor ID: AuthenticAMD
CPU family: 23
Model: 113
Model name: AMD Ryzen 9 3950X 16-Core Processor
Stepping: 0
Frequency boost: enabled
CPU MHz: 2680.379
CPU max MHz: 4761.2300
CPU min MHz: 2200.0000
BogoMIPS: 6986.90
Virtualization: AMD-V
L1d cache: 512 KiB
L1i cache: 512 KiB
L2 cache: 8 MiB
L3 cache: 64 MiB
NUMA node0 CPU(s): 0-31
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Not affected
Vulnerability Retbleed: Mitigation; untrained return thunk; SMT enabled with STIBP protection
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Retpolines, IBPB conditional, STIBP always-on, RSB filling
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc rep_good nopl nonstop_tsc cpuid extd_apicid aperfmperf rapl pni pclmulqdq monitor ssse3 fma cx16 sse4_1 sse4_2 movbe popcnt aes xsave avx f16c rdrand lahf_lm cmp_legacy svm extapic cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw ibs skinit wdt tce topoext perfctr_core perfctr_nb bpext perfctr_llc mwaitx cpb cat_l3 cdp_l3 hw_pstate ssbd mba ibpb stibp vmmcall fsgsbase bmi1 avx2 smep bmi2 cqm rdt_a rdseed adx smap clflushopt clwb sha_ni xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local clzero irperf xsaveerptr rdpru wbnoinvd arat npt lbrv svm_lock nrip_save tsc_scale vmcb_clean flushbyasid decodeassists pausefilter pfthreshold avic v_vmsave_vmload vgif v_spec_ctrl umip rdpid overflow_recov succor smca sme sev sev_es検証用データ生成
import (
"math/rand"
)
N := 2048
veca := make([]float32, N)
vecb := make([]float32, N)
for i := 0; i < N; i++ {
veca[i] = rand.Float32()
vecb[i] = rand.Float32()
}ベンチマークコード
import (
"testing"
"reflect"
"runtime"
)
runtime.GOMAXPROCS(1)
func bench(f func() float32) func(b *testing.B) {
return func(b *testing.B) {
for i := 0; i < b.N; i++ {
f()
}
}
}
type Result struct {
Size int
Benchmark map[string]testing.BenchmarkResult
}
results := []Result{}
for _, size := range []int{32, 256, 2048} {
type BenchmarkFunc struct {
Name string
Func func(a, b []float32) float32
}
curVeca := veca[:size]
curVecb := vecb[:size]
bs := map[string]testing.BenchmarkResult{}
for _, e := range []BenchmarkFunc{
{Name: "CalcDot", Func: CalcDot},
{Name: "CalcDotUnroll2", Func: CalcDotUnroll2},
{Name: "CalcDotUnroll4", Func: CalcDotUnroll4},
{Name: "CalcDotUnroll8", Func: CalcDotUnroll8},
{Name: "CalcDotByGonumBlas", Func: CalcDotByGonumBlas},
{Name: "CalcDotByWeaviateAsm", Func: CalcDotByWeaviateAsm},
} {
bs[e.Name] = testing.Benchmark(bench(func() float32 {
e.Func(curVeca, curVecb)
}))
}
results = append(results, Result{Size: size, Benchmark: bs})
}ベンチマーク結果
Code
import (
"fmt"
"sort"
"strings"
)
func calcNsPerOp(b *testing.BenchmarkResult) uint64 {
return uint64(b.T) / uint64(b.N)
}
func makeRow(funcName string, benchmark *testing.BenchmarkResult) string {
nsPerOp := calcNsPerOp(benchmark)
return fmt.Sprintf("<tr><td>%s</td><td>%d</td><td>%d</td><td>%d</td></tr>", funcName, benchmark.N, benchmark.T, nsPerOp)
}
func makeTable(results map[string]testing.BenchmarkResult, size int) string {
var rows []string
for name, result := range results {
rows = append(rows, makeRow(name, &result))
}
sort.Strings(rows)
return fmt.Sprintf(`<table class="dataframe"><caption>size=%d</caption><tr><th>関数名</th><th>回数</th><th>時間[ns]</th><th>1回あたりの時間[ns]</th></tr>%s</table>`, size, strings.Join(rows, "\n"))
}
tables := []string{}
for _, r := range results {
tables = append(tables, makeTable(r.Benchmark, r.Size))
}
display.HTML(strings.Join(tables, "\n"))| 関数名 | 回数 | 時間[ns] | 1回あたりの時間[ns] |
| CalcDot | 346974 | 1179908231 | 3400 |
| CalcDotByGonumBlas | 336958 | 1204222744 | 3573 |
| CalcDotByWeaviateAsm | 457072 | 1118602599 | 2447 |
| CalcDotUnroll2 | 319407 | 1289024805 | 4035 |
| CalcDotUnroll4 | 353758 | 1322124380 | 3737 |
| CalcDotUnroll8 | 375663 | 1259082336 | 3351 |
| 関数名 | 回数 | 時間[ns] | 1回あたりの時間[ns] |
| CalcDot | 92368 | 1205821911 | 13054 |
| CalcDotByGonumBlas | 341826 | 1239509464 | 3626 |
| CalcDotByWeaviateAsm | 458673 | 1126861958 | 2456 |
| CalcDotUnroll2 | 72632 | 1251829756 | 17235 |
| CalcDotUnroll4 | 86812 | 1227783225 | 14143 |
| CalcDotUnroll8 | 93368 | 1228300326 | 13155 |
| 関数名 | 回数 | 時間[ns] | 1回あたりの時間[ns] |
| CalcDot | 13098 | 1214307203 | 92709 |
| CalcDotByGonumBlas | 320077 | 1216720203 | 3801 |
| CalcDotByWeaviateAsm | 439030 | 1119375941 | 2549 |
| CalcDotUnroll2 | 9525 | 1176658556 | 123533 |
| CalcDotUnroll4 | 12124 | 1188543785 | 98032 |
| CalcDotUnroll8 | 13207 | 1200212236 | 90876 |
Code
import (
"math"
"bytes"
"gonum.org/v1/plot"
"gonum.org/v1/plot/plotter"
"gonum.org/v1/plot/plotutil"
"gonum.org/v1/plot/vg"
"gonum.org/v1/plot/vg/draw"
)
func displayPlot(p *plot.Plot) {
var buf bytes.Buffer
c, err := p.WriterTo(6*vg.Inch, 6*vg.Inch, "png")
if err != nil {
panic(err)
}
if _, err := c.WriteTo(&buf); err != nil {
panic(err)
}
Display(display.PNG(buf.Bytes()))
}
p := plot.New()
p.Title.Text = "Benchmark of dot product"
p.X.Label.Text = "Function"
p.Y.Label.Text = "Duration per op[ns]"
p.X.Tick.Label.Rotation = math.Pi / 2.5
p.X.Tick.Label.XAlign = draw.XRight
p.Legend.Top = true
names := []string{}
for name, _ := range results[0].Benchmark {
names = append(names, name)
}
sort.Strings(names)
p.NominalX(names...)
for i, r := range results {
var values plotter.Values
for _, name := range names {
b := r.Benchmark[name]
values = append(values, float64(calcNsPerOp(&b)))
}
bar, _ := plotter.NewBarChart(values, vg.Points(20))
bar.LineStyle.Width = vg.Length(0)
bar.Color = plotutil.Color(i)
bar.Offset = vg.Points(float64(i - 1) * 20)
p.Add(bar)
p.Legend.Add(fmt.Sprintf("size=%d", r.Size), bar)
}
displayPlot(p)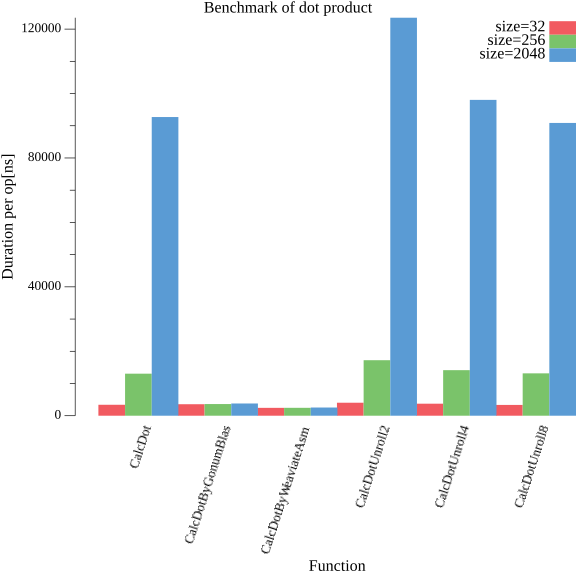
まとめ
すべての測定でWeaviateのアセンブリ実装が最速であることがわかりました。
参考
[1]
Weavite. GitHub repository. https://github.com/semi-technologies/weaviate; GitHub.
[2]
Tokyo, W.W.G. 2021. Go言語を楽しむ5つのレシピ: コタツと蜜柑とゴーファーとわたし. インプレスR&D.